






– Proces zniechęcania kobiet do nauk ścisłych zaczyna się jeszcze w szkole podstawowej, kiedy wmawia się dziewczynom, że tylko z powodu swojej płci nie mogą być dobre z matematyki. Kiedyś w gimnazjum usłyszałam, że „na mat-fizie to są same babochłopy”. Dlatego od podstawówki trzeba zadbać, aby dziewczęta nie wstydziły się, że lubią matematykę – zauważa Karolina Drabent, członkini i była prezeska stowarzyszenia ML in PL.
Karolina Drabent była prezeską, a obecnie jest członkinią stowarzyszenia ML in PL – organizacji skupiającej pasjonatów uczenia maszynowego na polskich uczelniach, którzy promują i rozwijają machine learning w Polsce. ML in PL to też organizator jedynej w Polsce i największej w regionie Europy Środkowo-Wschodniej konferencji poświęconej kwestiom machine learning na styku nauki i biznesu. Karolina jest w trakcie uzyskania tytułu magistra na Uniwersytecie w Amsterdamie, gdzie zgłębia tajniki świata sztucznej inteligencji.
Jaki był najciekawszy projekt, w którym brałaś udział?
Temat, który nie został ukończony przez pandemię, a który bardzo mi się podobał, to klasyfikacja szkiców. Wizja komputerowa wydaje mi się obecnie mniej interesująca, ale akurat rysunki są bardzo ciekawe, ponieważ każdy w inny sposób oddaje esencję tego, co widzi. Z kolei kiedy byłam na stażu w Samsungu, zainteresowałam się tematyką humoru i próbami zrozumienia go przez algorytmy. To jeden z aspektów, które odróżniają człowieka od sztucznej inteligencji. Jeśli dojdziemy do etapu, kiedy AI zrozumie, czym jest humor, będziemy mogli lepiej porozumiewać się z tą technologią. W przyszłości chciałabym się zająć algorytmami przetwarzania języka naturalnego i algorytmami grafowymi, a także wykorzystaniem machine learning do planowania przestrzeni miejskiej.
Czyli twoja kariera będzie związana z machine learning. Planujesz coś konkretnego?
Mam oczywiście jakiś plan, choć nie oznacza to, że będę się go kurczowo trzymała. Chciałabym zacząć studia doktoranckie, ale po wysłuchaniu różnych opowieści myślę, że nie będę robiła tego w Polsce. Kiedy rzucałam studia magisterskie w Polsce, wszyscy mi to odradzali, bo twierdzili, że nie będzie mi się chciało wracać. To dość częste podejście w naszym kraju, bo ludzie uważają, że trzeba zrobić wszystko naraz, co moim zdaniem nie jest najlepszym rozwiązaniem.
Kiedy zaczęłam studia w Holandii i mi się spodobały, pomyślałam, że spróbuję kontynuować karierę naukową. Lubię też uczyć, więc jeśli mogłabym kiedyś wykładać, byłoby to świetnym rozwiązaniem. Wiadomo, że w sektorze prywatnym zarabia się więcej, zatem nie wiem, czy w pewnym momencie ten argument nie przekona mnie do zmiany zdania. Zresztą zawsze można próbować łączyć obie aktywności. Chciałabym też kiedyś spróbować swoich sił na stanowisku zarządzającym ze względu na moje doświadczenie w ML in PL i satysfakcję z organizowania różnych przedsięwzięć, a także robienia czegoś dla innych ludzi.
Masz jakiś pomysł na zainteresowanie nowych osób światem machine learning?
Mam nadzieję, że stowarzyszenie ML in PL, którego jestem członkinią, a przez pewien czas byłam też prezeską, ciągle będzie się rozwijać. Dużą moc mają różnego rodzaju meetupy, spotkania, gdzie buduje się społeczność, a także prowokuje ludzi do myślenia i rozmawiania na temat machine learning. Konferencje są również świetne, ale ich wadą jest to, że odbywają się raz na rok, a warto się spotykać częściej. Innym pomysłem, już realizowanym, są letnie szkoły. Niedługo też pojawi się nowa inicjatywa ML in PL, o której jeszcze na pewno usłyszymy.
W rozwój i promowanie ML w Polsce powinny się włączyć również uczelnie, np. poprzez różnego rodzaju konkursy, ale przede wszystkim przez organizację dobrze prowadzonych przedmiotów związanych z uczeniem maszynowym. Słyszałam, że ostatnio Uniwersytet Warszawski uruchomił ciekawe studia magisterskie z praktycznymi przedmiotami dotyczącymi uczenia maszynowego. Jednak na efekty musimy poczekać, aż pierwsi studenci skończą ten kierunek i będą mogli powiedzieć więcej na ten temat.
Czy według ciebie jest jakiś konkretny sposób, który pomoże przyciągnąć więcej kobiet do nauk ścisłych?
Dobrym przykładem są inicjatywy fundacji Perspektywy, która m.in. organizuje konferencję Women in Tech Summit, aby zmienić wizerunek politechnik i nauk ścisłych jako przeznaczonych tylko dla mężczyzn. Brałam również udział w inicjatywie tej fundacji, ucząc dzieci programowania, co było bardzo ciekawym przeżyciem.
Warto jednak pamiętać, że proces zniechęcania kobiet do nauk ścisłych zaczyna się dużo wcześniej, np. w szkole podstawowej, kiedy wmawia się dziewczynom, że tylko z powodu swojej płci nie mogą być dobre z matematyki. Albo że chłopcom lepiej poszło na teście, bo są chłopcami. Kiedyś, jeszcze w gimnazjum, sama usłyszałam, że „na mat-fizie to są same babochłopy”. Dlatego aby odwrócić ten proces, trzeba zacząć już w podstawówce, aby dziewczęta nie wstydziły się, że lubią matematykę.
Na informatyce na moim roku było może z 10 proc. dziewczyn, przez co sama miałam “syndrom oszusta”, czyli czułam, że niekoniecznie powinnam tam być. Przez chwilę, kiedy studiowałam na Uniwersytecie Warszawskim, zauważyłam, że uczelnia zaczęła stosować feminatywy np. w korespondencji mailowej, co w moim odczuciu jest świetną decyzją.
Na szczęście nie miałam zbyt wielu seksistowskich przeżyć. Jednak te, które mnie spotkały, na pewno nie sprawiły, że czułam się tam przyjemniej. Dlatego lepiej by było, gdyby więcej prowadzących było bardziej świadomych tego, co mówią, i jaki to ma wpływ na młodych ludzi. Natomiast z opowieści znajomych, które studiują na innych uczelniach i kierunkach ścisłych, słyszałam, że bywa z tym znacznie gorzej.
Twoja praca dyplomowa dotyczyła generowania zapisu nutowego na podstawie nagrań rąk pianistów. Czy jeszcze nad tym pracujesz?
Nie. Mieliśmy na to za mało czasu – praca inżynierska to jedynie ostatnie pół roku z trzech i pół roku studiów. Poza tym nie miała ona charakteru badawczego, ponieważ zbyt dużą część pracy musieliśmy poświęcić na prezentację wyników i budowanie wielu funkcjonalności, a nie na opracowanie samego algorytmu.
Czy uważasz, że ktoś, kto nie ukończył studiów kierunkowych, może sobie poradzić w świecie machine learning?
Na pewno tak, ale będzie to ją lub jego kosztowało sporo czasu. Głównym wyzwaniem jest zrozumienie podstaw matematycznych, ale jeśli ktoś chce, to po prostu musi nauczyć się paru rzeczy, takich jak algebra liniowa, statystyka czy analiza matematyczna, szczególnie pochodne. Z tego powodu osoby, które skończyły studia matematyczne, nie powinny mieć problemu z ML. Z drugiej strony jest część związana z programowaniem, którą trzeba w pewien sposób przyswoić, ale też niekoniecznie na jakimś bardzo wysokim poziomie. W praktyce używa się głównie Pythona z odpowiednimi bibliotekami programistycznymi.
Co byś powiedziała komuś, kto chciałby się zająć machine learning?
Dużo zależy od tego, co taka osoba lubi robić. Czy widzi siebie jako inżyniera, który będzie stosował różne rozwiązania, czy jako kogoś, kto chce robić research. W tym drugim wypadku warto rozważyć wyjazd za granicę, ponieważ tam podejście do researchu jest znacząco inne. Niestety na niekorzyść polskich uczelni, choć mam nadzieję, że z czasem będzie się to zmieniać. Można też zrobić tak jak ja i w Polsce zrobić inżynierkę, a dopiero potem wyjechać.
Myślę, że mimo wszystko sporo się nauczyłam. Dobre podstawy pod AI i ML, tak jak wspomniałam, dadzą również studia matematyczne. Polecam poznać podstawy programowania, które z pewnością się przydadzą. Warto czytać różne opracowania naukowe, a także pamiętać, że ML można zastosować w wielu dziedzinach i przydatna może się okazać wiedza z takich obszarów jak chemia, medycyna, a nawet literatura.
Czy są rozwiązania w środowisku machine learning, które dziś są szczególnie popularne?
Obecnie dużo osób zajmuje się sieciami grafowymi, ponieważ wiele zbiorów danych to grafy. Natomiast jakiś czas temu powstała sieć Transformers, która poruszyła osoby zajmujące się przetwarzaniem tekstu (ang. natural language processing, NLP) ze względu na dużo lepsze wyniki.
Jakie widzisz wyzwania dla obszaru machine learning?
Do głównych na pewno należą etyczność algorytmów, wytłumaczalność i kwestie klimatyczne. Algorytmy są takie, jakie są nasze dane, dlatego jeśli znajdzie się w nich np. dużo przekleństw albo pojawią się rasistowskie sformułowania, to algorytm też będzie taki. Tzw. bias można zaobserwować nawet w tłumaczu Google, który zdanie “I cooked the dinner” tłumaczy czasami jako “ugotowałam obiad”, ale już “I worked as a programmer” jako “pracowałem jako programista”. Innym wyzwaniem jest duży koszt obliczeniowy uczenia maszynowego, związany z dużym zapotrzebowaniem na energię i wydzielaniem ciepła, co ma z kolei wpływ na środowisko.
Obecnie studiujesz w Amsterdamie. Czy widzisz jakieś różnice w porównaniu ze studiami w Warszawie?
W Holandii jestem dopiero piąty miesiąc na studiach magisterskich. Czuję się tu dobrze, choć oczywiście jest inaczej, ale mi to nie przeszkadza, bo bardzo lubię zmiany. Wcześniej studiowałam na dwóch polskich uczelniach, gdzie miałam poczucie, że wydział niespecjalnie przejmuje się studentami. Niby są przeprowadzane różnego rodzaju ankiety na temat kursów i prowadzących, ale wątpię, że ma to realny wpływ na rzeczywistość.
W Amsterdamie jest inaczej: na mojej uczelni każdy semestr jest podzielony na trzy bloki, podczas których zalicza się część przedmiotów. W momencie kiedy studenci zgłaszają uwagi, że są zbyt obciążeni materiałem, prowadzący reagują na taki feedback i np. skracają zadania lub projekty albo biorą pod uwagę tylko część projektów, które zostały najlepiej zaliczone. Dlatego mam poczucie, że w Holandii uczelnie bardziej przejmują się zdaniem studentów.
Innym pozytywnym wrażeniem jest to, że kurs, w którym uczestniczę, jest na naprawdę wysokim poziomie. Nie jestem tym bardzo zaskoczona, ale cieszę się, że zajmuję się rzeczami, o których chciałam się uczyć, m.in. sieciami neuronowymi, ich różnymi architekturami i nowymi modelami, czyli najciekawszymi rzeczami, które się teraz pojawiają. Już w pierwszych miesiącach studiowania mieliśmy styczność z zagadnieniami sieci rekurencyjnych, grafowych czy konwolucyjnych. Robimy dokładnie to, co nam się przyda w przyszłości.
Dla porównania, na moim poprzednim wydziale w Polsce sieci neuronowe pojawiają się dopiero pod koniec studiów. Tam po trzech miesiącach nie miałam w ogóle styczności z sieciami neuronowymi, ponieważ zajmowaliśmy się rzeczami sprzed 20 czy 30 lat, takimi jak np. algorytmy rojowe, mrówkowe etc. Oczywiście to są również ciekawe tematy i wspaniale mieć świadomość, że coś takiego istnieje, ale obecnie nie powinno to być centrum programu nauczania.
Jak wyglądają studia z machine learning, na których obecnie jesteś?
Trwają dwa lata. Wykłady, stacjonarne lub zdalne, prowadzone są przez Zoom. Są też nieobowiązkowe odpowiedniki znanych z polskiego systemu ćwiczeń i laboratoriów. Poza tym mamy projekty czy też zadania, które trzeba zrobić. W zasadzie nie spotkałam się z kimś, kto by powiedział, że na tych studiach jest za mało do robienia, ponieważ jest naprawdę wiele projektów.
Zadania można podzielić na bardziej teoretyczne i praktyczne, czyli związane np. z programowaniem. Jest bardzo dużo matematyki, co jest dość wymagające i wyczerpujące, ale z drugiej strony potrzebne, bo mamy dużo większą świadomość tego, co robimy. Projekty możemy też podzielić na grupowe i samodzielne. Podczas ćwiczeń i laboratoriów możemy zadawać pytania dotyczące m.in. kwestii związanych z projektami, więc mamy wsparcie prowadzących. Czasem też prowadzą oni tutoriale z wprowadzeniem w temat lub pokazują, jak rozwiązywać bardzo podobne zadania, abyśmy mieli odpowiednie odniesienie.
Wcześniej, kiedy studiowałam informatykę na Politechnice Warszawskiej, na początku była głównie matematyka, potem mieliśmy coraz więcej projektów, które mam wrażenie, że były dużo luźniej zdefiniowane, np. mieliśmy „zakodzić” algorytm i opakować go w interfejs graficzny (GUI), ale bardzo rzadko w wymaganiach podawano dużo więcej. Na obecnych studiach dostaję gotowy opis tego, co mamy zrobić, w którym miejscu. Z jednej strony to jest przyjemne, ponieważ uczę się konkretnych architektur, a celem jest zrozumienie, jak one działają. Przykładem jest LSTM i kodowanie bez korzystania z zaawansowanych struktur biblioteki PyTorch, dzięki czemu można się więcej dowiedzieć, ale mam nadzieję, że w pewnym momencie będziemy mieli większą dowolność w wyborze projektów.
A jak porównasz kontakt z innymi studentami? Masz odczucie, że jest inaczej?
Tak, są pewne różnice. Zarówno w Polsce, jak i w Holandii, obecnie trwa kolejna fala pandemii, jednak tu mimo wszystko możemy przyjść do kampusu i uczestniczyć w większości wykładów. W Holandii mamy teraz częściowy lockdown, tzn. puby zamykają się o 17, a sklepy o 20, jednak uniwersytet jest normalnie otwarty. Dzięki temu, że ja i pewnie wiele innych osób czujemy się dużo lepiej, bo jednak wspólna praca, kiedy siedzimy przy jednym stole, jest bardziej udana. Poza tym jest to też ważną częścią życia studenckiego.
Poza pandemią pewną różnicą jest też to, że w Polsce, jeśli ktoś poszedł na informatykę, to kontynuuje zazwyczaj naukę aż do magisterki. Tu jednak widzę sporo osób, które wcześniej robiły wiele innych rzeczy – na przykład zajmowały się lotnictwem czy komunikacją. Sporo z nich jest też po licencjacie z AI. Mówię to po to, aby podkreślić, że ludzie są bardziej zróżnicowani i jest większy wybór kierunków, które można studiować. Nie chciałabym, aby to zabrzmiało źle, ale mam wrażenie, że na informatyce w Polsce jest dużo ludzi, którzy są zamknięci w sobie, tu z kolei są bardziej otwarci i społeczni.
Czy w takim razie widzisz różnicę pomiędzy pracą zespołową na studiach w Polsce i w Holandii?
Kiedy studiowałam w Polsce, miałam grupę znajomych, z którymi robiliśmy projekty. Kiedy jednak zdarzyło się, że pracowałam z kimś innym, to trudniej mi było nawiązać kontakt. Jako ekstrawertyczka czuję, że na studiach w Holandii, pomimo że miałam mniej projektów grupowych, mam z kim porozmawiać.
Czy masz jakieś doświadczenie związane z machine learning na polskich uczelniach, które najbardziej zapadło ci w pamięć?
Moja przygoda z ML zaczęła się na drugim roku studiów, kiedy kolega mi powiedział, że istnieje coś takiego, co mnie zainteresowało, i sama zaczęłam się tego uczyć – wówczas nie miałam możliwości, aby cokolwiek wybierać na studiach. Byłam też w kole naukowym i był to rok, w którym poszłam na pierwszą konferencję ML in PL. Uważam to za bardzo dobrą decyzję, bo co prawda można uczyć się samemu, ale warto być w miejscu, gdzie są ludzie, którzy interesują się tym samym. To ma szczególne znaczenie, jeśli chcesz zgłębić temat, o którym nie wiesz zbyt wiele. Przyjemnie jest posłuchać, jakie są możliwości.
Potem wybrałam dwa przedmioty związane z uczeniem maszynowym – jeden z przetwarzaniem tekstu, a drugi to po prostu “uczenie maszynowe”, oba prowadzone przez moją promotorkę. Mogłam na nich zrobić projekty, które pomogły mi wdrożyć się w temat. Czuję niedosyt przez to, że nie było więcej przedmiotów związanych z uczeniem maszynowym, które mogłam wybrać. Później wybrałam jeszcze zajęcia o przetwarzaniu obrazu, ale tam właściwie nie było nic związanego z uczeniem maszynowym, co trochę zaskakuje, jeśli wziąć pod uwagę, jakie znaczenie ma ML w tym obszarze. Na ostatnim semestrze miałam jeszcze jeden przedmiot na temat AI, ale w ogóle nie było na nim zagadnień z zakresu machine learning, tylko stare metody.
Mówisz dość krytycznie o machine learning na studiach w Polsce, a mimo to coś cię przekonało do tego, aby pójść w tym kierunku.
Sam temat wydaje mi się ciekawy i chciałam się dowiedzieć czegoś więcej. A to, że nie był on zbyt dobrze prowadzony na mojej uczelni, nie znaczy, że gdzie indziej jest podobnie. Po prostu byłam zdeterminowana i się nie poddawałam.
– Python jest dobry do klejenia różnych klocków w całość, ale nie nadaje się do implementacji nowych algorytmów, które liczą się zbyt wolno. W efekcie są one implementowane w C++, gdzie trzeba się dużo napracować, bo język ten nie jest przystosowany do analiz matematycznych. Alternatywą dla combo C++ i Python jest język Julia, która świetnie się sprawdza zarówno w modelowaniu procesów analitycznych, jak i wdrożeniu własnych algorytmów. Często jest dużo „szybsza” od innych języków.
O technologiach wspierających data scientistów, rozwijaniu niegdyś egzotycznego języka programowania, a także sposobach na zastosowanie zdobyczy data science przez przedsiębiorców rozmawiamy z dr. Przemysławem Szuflem – adiunktem w Zakładzie Wspomagania i Analizy Decyzji Szkoły Głównej Handlowej w Warszawie oraz współpracownikiem Laboratorium Badań nad Bezpieczeństwem Cybernetycznym w Ted Rogers School of Management na Uniwersytecie Ryersona w Toronto, partnerem zarządzającym funduszu VC Nunatak Capital. Dr Szufel jest też ekspertem i pasjonatem języka programowania Julia, współautorem książki pt. „Julia 1.0 Programming Cookbook”, a także jednym z najbardziej szanowanych ekspertów na portalu Stackoverflow.com, który rozwija język Julia.
Naukowo zajmuje się Pan obszarem analizy decyzji. Porozmawiajmy więc o analityce, ale w zakresie data science. O czym się teraz najczęściej mówi na świecie?
Głównie o narzędziach wykorzystujących szeroko pojętą sztuczną inteligencję. Chodzi o gotowe komponenty do rozpoznawania twarzy czy głosu, ale też zamieniające mowę na tekst i przetwarzające naturalny język. Jest teraz taki trend, by zamiast samodzielnie tworzyć algorytmy, wykorzystywać w zamian gotowe klocki. I tu trzeba wspomnieć o rozwijających się rozwiązaniach typu AutoML. Opierają się one na tym, że niejako same pobierają dane i automatycznie do nich przymierzane są modele. Dzieje się to bez konieczności zajmowania się procesem modelowania.
Zobrazujmy to sobie. Mogę wziąć historyczne dane z kampanii marketingowej, „wrzucić” je do tzw. czarnego pudełka, którym jest AutoML. W rezultacie otrzymam informacje oraz model prognostyczny, którzy klienci i w jaki sposób reagowali na daną kampanię reklamową oraz na dany produkt.
Albo inny przykład, tym razem z bankowości. Mamy dane o kredytach i zaciągniętych pożyczkach. Znajduje się tam także przekrój informacji na temat poszczególnych klientów. AutoML wygeneruje nam model, który jest w stanie oszacować, jakie jest prawdopodobieństwo, że dana osoba zwróci kredyt. Narzędzia AutoML pozwalają generować modele znacznie mniejszym nakładem pracy i w efekcie przyczyniać się do zmniejszania liczby zatrudnionych analityków danych. Niestety, nie ma róży bez kolców – nie każdy problem ma strukturę pozwalającą na jego rozwiązanie standardowym automatycznym narzędziem. I chyba dobrze, że tak jest, bo dzięki temu najciekawsze problemy trafiają ciągle do ludzi, a nie do maszyn.
Skoro modele matematyczne potrafią ułatwić wiele procesów, to czy wykorzystanie ich w pracy z Pana studentami jest możliwe i efektywne? Na przykład przy ocenach?
Ocena studenta to wyjątkowa materia, która wymaga często czegoś więcej niż system. Ale faktycznie, staram się korzystać z pewnego rodzaju automatycznego rozwiązania. Weryfikuje ono zadania z zakresu wykładanego przeze mnie przedmiotu Cloud Computing oraz to, czy zostały w odpowiedni sposób rozwiązanie i opublikowane w chmurze.
Stawiam na praktykę, choć jednocześnie wyznaję zasadę, że bez teorii nie ma mowy o praktyce, a znajomość podstawowych definicji, praw i zależności jest niezbędna, by dobrze wykonywać zadania.
No dobrze, chmura potrafi przetwarzać ogrom danych na niespotykaną wcześniej skalę. Mamy jednak pytanie o ich wartość – czy rzeczywiście da się ich wszystkich użyć z korzyścią dla użytkownika?
Dane mogą nam pomóc w znalezieniu odpowiedzi na wiele pytań i podjęciu właściwych decyzji. Jednak same w sobie nie dają wartości. Najpierw trzeba je przetworzyć. Od danych do informacji i wiedzy jest dość długa droga. Celem procesu analitycznego, a więc procesu data science jest to, by od punktu, gdzie mamy surowe dane, dojść do punktu, gdzie możemy podjąć jakąś decyzję, zamienić naszą wiedzę w konkretne działanie. Strasznie ciekawe w danych jest to, że można je modelować matematycznie. Modele te mogą być przedmiotem eksperymentów lub optymalizacji i w efekcie za ich pomocą można objaśniać, jak działa świat.
Czy język Julia, który Pan popularyzuje, też potrafi wytłumaczyć, dlaczego świat działa w taki sposób, a nie inny?
Oczywiście! Julia 1.0 miała premierę w 2018 roku, a więc jest to narzędzie stosunkowe młode. W data science zmieniło to, że wypełniło pewną lukę na rynku. Obecnie najpopularniejszym narzędziem do łączenia poszczególnych komponentów procesu analitycznego jest język Python. Ale jeśli te różne klocki musi stworzyć lub zaimplementować wymyślony przeze mnie algorytm, to Python nie jest już w stanie tego efektywnie zrobić. Inaczej ma język Julia.
Badacze z Massachusetts Institute of Technology w nauce numerycznej nazywają to problemem z dwujęzycznością. O ile Python jest dobry do klejenia kodu w jedną całość, o tyle tworzenie w nim poszczególnych algorytmów jest dość problematyczne. Alternatywą dla popularnego dotychczas combo języków C++ i Python jest język Julia. Dzięki swojej elastyczności pozwala używać dowolnej biblioteki Pythona, ma również podobną składnię. Python jest stosunkowo wolny – nawet 30 razy wolniejszy niż ten sam kod w języku C++, podczas gdy Julia kompiluje się bezpośrednio do kodu maszynowego rozumianego przez procesor komputera. Dokładnie tak samo jak szybki C++. Mogę więc korzystać z wielu efektywnych cech, którymi dysponuje ten język, a przy tym dysponować szybszym w działaniu narzędziem. I to jest właśnie Julia.
Pana dorobek w obszarze języka Julia to światowa klasa! Jak stał się Pan specjalistą w tym obszarze?
Do świata Julii trafiłem bardzo prosto, ponieważ zajmuję się analizami numerycznymi i wielkoskalowym przetwarzaniem danych. Znam Javę, ale nie jest ona przystosowana do analiz matematycznych. Mogłem wybrać Pythona, ale tam z kolei modele liczyły się bardzo wolno. Okazało się, że do implementowania własnych algorytmów idealny okazał się język Julia – wówczas jeszcze w wersji beta.
Wspólnie z kolegą z SGH, profesorem Bogumiłem Kamińskim, napisaliśmy też o niej książkę pt. „Julia 1.0 Programming Cookbook”, która została przetłumaczona na język japoński. Na co dzień prowadzę szkolenia. m.in. w ramach współpracy ze Szkołą Główną Handlową i z Narodowym Bankiem Polskim. Mogę też zdradzić, że NBP w tym momencie idzie śladem innych banków centralnych na świecie i wdraża język Julia do analiz makroekonomicznych. Co ciekawe, szkolenie z języka Julia dla polskiego banku centralnego współprowadziłem już w roku 2019, a więc kilkanaście miesięcy po ukazaniu się wersji 1.0 języka. Pokazuje to, jak bardzo innowacyjna i otwarta na nowe technologie jest ta instytucja.
Nawiązując do tytułu Pana książki o języku Julia – czy z algorytmami jest jak z gotowaniem?
Zdecydowanie. Mieliśmy zamysł skonstruować książkę o zaawansowanym języku programowania tak, jakbyśmy chcieli stworzyć książkę kucharską. To trochę wyjście naprzeciw zasadzie „learning by doing” – na podstawie przykładów pokazujemy, jak robić różnego rodzaju rzeczy. W ten sposób działa właśnie portal Stackoverflow.com, który zrzesza programistów, informatyków, analityków. Ludzie zadają pytania i dostają odpowiedzi. W przypadku informatyki pokazywanie rzeczy naocznie bardzo dobrze działa. Zaczynanie od teorii i omawianie wszystkich możliwych rzeczy, które da się zaprogramować, byłoby zwyczajnie nieefektywne.
Jest Pan zewnętrznym konsultantem w dziedzinie data science. Rozmawialiśmy o dużej firmie, która dzięki zaprojektowanemu rozwiązaniu na bazie języka Julia poprawiła funkcjonowanie podstawowych procesów biznesowych.
To dość banalne, ale prawdziwe: data science prawidłowo użyte łączy się z biznesem, a nieprawidłowo używane tego nie robi. W biznesie data science ma swój cel, którym najczęściej jest optymalizacja. Za optymalizacją idą konkretne pieniądze, które można zarobić lub zainwestować.
Wraz z profesorem Piotrem Ciżkowiczem miałem okazję zbudować pewien model dla jednego z największych w Europie producentów rowerów – firmy Kross. Swoją drogą, chyba najbardziej innowacyjnej firmy rodzinnej w Polsce. Celem było wyprodukowanie jak największej liczby rowerów przy utrudnionej dostępności poszczególnych części. Kłopoty wynikały z zaburzeń w logistyce – brakowało hamulców, amortyzatorów, a nawet farby do malowania. Jednocześnie był duży popyt, więc należało znaleźć receptę na biznes w rzeczywistości niedoborów.
W modelu, który zbudowaliśmy, zebrane zostały najpierw dane dostępne w spółce o procesach produkcyjnych, o liniach produkcyjnych, o tym, z czego się składają rowery, o możliwościach dostawcy… Łącznie ponad 4 mln zmiennych decyzyjnych i ponad 100 mln warunków ograniczających. Tutaj chodzi o dostępność i przepustowość linii produkcyjnej, możliwości zakładu czy pracowników. Ostatecznie powstał model, który wskazuje, kiedy, ile, jakich rowerów i dla kogo należy produkować. To, że ktoś jeździ teraz czerwonym lub zielonym rowerem wyprodukowanym przez Kross, jest efektem decyzji, którą podjął ten nasz model. Dzięki jego wdrożeniu wzrosła rentowność całej fabryki o 10 proc., co bez wątpienia przełożyło się na wynik finansowy spółki.
Ciekawe, w jakim stopniu podobne zakłady mogłyby obniżyć koszty produkcji i zwiększyć przychody, gdyby firma dysponowała podobnym modelem wcześniej… Choć pewnie takie, które już na starcie stawiają na data science, mogą się nie martwić o kwestię optymalizacji.
I takie właśnie spółki bierzemy pod swoje skrzydła w ramach funduszu VC Nunatak Capital, którego też jestem współwłaścicielem.
Jak wygląda obecnie inwestowanie w takie spółki?
W świecie start-upów technologicznych co drugi chce dziś być „data science”. W moim odczuciu jest to już pewnego rodzaju buzzword, czyli pojęcie bardzo modne, a czasami pewnie też nadużywane.
Dla nas cenne są firmy, które budują swoją wartość wokół data science. Mamy nietypowy model działalności, bo korzystamy jedynie z pieniędzy prywatnych. Dzięki temu pojawiają się nowe możliwości i znikają ograniczenia, które są np. przy korzystaniu z państwowego finansowania. W przypadku projektów data science często chodzi nie tylko o trafność, ale i szybkość podejmowania decyzji, w naszym przypadku inwestycyjnych. Tutaj trzeba wykazać się elastycznością, która jest nieodłącznym elementem procesu inwestycyjnego.
Czy obserwuje Pan trend, że fundusze VC przychylniej patrzą dziś na firmy oferujące produkty i rozwiązania z jakiegoś konkretnego obszaru?
Przede wszystkim opłaca się inwestować tam, gdzie oczekujemy szybkiego wzrostu. Start-upy, które obecnie dobrze się rozwijają, to takie, które pozwalają na automatyzację uciążliwych procesów. Chodzi o kwestie dotyczące zarówno ludzi, jak i ich codzienności, ale też procesów w firmach.
Podam przykład procesu zarządzania umowami. W naszym portfelu znajduje się start-up, który oferuje automatyzację tworzenia, konstruowania i gromadzenia plików z umowami w różnych działach firmy. Ich narzędzie pozwala na zarządzanie treścią umowy, dołączanie skomplikowanych klauzul i zapisów do umów. Ujednolica także formaty i sposoby podpisywania dokumentów. Wykonywanie tych czynności jest czasochłonne i nieefektywne, a z takim narzędziem wszystko jest w jednym miejscu i ułatwia działanie firmy.
Rosną także start-upy, które dostarczają oprogramowanie dla klientów moich klientów (ang. client of a client). Przykładem jest firma z naszego portfela tworząca aplikację dla żłobków i przedszkoli, z której realnie korzystają rodzice dzieci. Z jednej strony jest to system do zarządzania przedszkolem, który dyrektor i tak musiałby prowadzić, np. w Excelu. Z drugiej strony służy do komunikacji z rodzicami zamiast wysyłania wielu maili. Tu każdy rodzic dostaje informacje o dziecku w czasie rzeczywistym – o tym, że zjadło obiad czy zasnęło w porze drzemki.
Mówi Pan o realnym zastosowaniu data science w codziennym życiu. Tylko czy to nadal ma coś wspólnego z nauką? Gdzie w określeniu „data science” jest miejsce na „science”?
To jest właśnie najpiękniejsza rzecz w uprawianiu nauki. Bo wszystko polega na znajdowaniu zależności, jak poszczególne komponenty nachodzą na siebie, jak mogą na siebie wpływać i co ostatecznie można z nich stworzyć. Raz będzie to zaawansowany model, raz aplikacja, a raz – sposób na usprawnienie biznesu.
To nieodłączna właściwość data science, która daje całościowe spojrzenie na rzeczywistość dzięki przeplataniu się nauki i informacji, które finalnie prowadzą do wiedzy, wartości i lepszej rzeczywistości.
– Fintechy mają zupełnie inne modele scoringowe. Na tym polega ich know-how. Data science w fintechach pozwala przejmować klientów „niezagospodarowanych” przez banki. Firma odrzucona wcześniej przez bank z uwagi na brak historii kredytowej nagle zyskuje dostęp do pieniędzy. Algorytmy fintechowe są też precyzyjniejsze w określaniu niepewności, oferują usługę taniej i szybciej. Czy tak samo bezpiecznie jak w banku? Nie jestem pewna – mówi dr hab. Aneta Hryckiewicz, badaczka data science w sektorze usług finansowych z Akademii Leona Koźmińskiego.
Dr hab. Aneta Hryckiewicz jest szefową Zakładu Ekonomicznych Analiz Empirycznych w Akademii Leona Koźmińskiego, gdzie prowadzi kierunek studiów Master in Big Data Science. Zajmuje się analizą trendów w sektorze finansowym, bada również wpływ nowych technologii i rozwiązań data science w fintechach na funkcjonowanie i strukturę sektora finansowego. Doświadczenie zawodowe zdobywała w jednym z największych banków inwestycyjnych, pracując przy fuzjach i przejęciach dużych przedsiębiorstw. Doradzała również wielu polskim firmom w zdobyciu kapitału oraz restrukturyzacji.
Jak zmienił się świat finansów po tym, jak odkrył dla siebie moc algorytmów sztucznej inteligencji i rozwiązań data science w fintechach?
W fintechach i bigtechach, które popychają digitalizację, ludzkie analizy są zastępowane algorytmicznymi. Roboty mogą szybko i sprawnie zaoferować produkty finansowe. W przypadku decyzji kredytowych mówimy o paru minutach, może 1-3 dniach, gdy chodzi o firmy. Tymczasem w instytucjach bankowych niekiedy trwa to tygodniami. Wygoda i szybkość są szczególnie ważne dla firm z problemami płynnościowymi, które muszą natychmiast pozyskać finansowanie, bo każdy kolejny dzień przybliża ich do bankructwa.
Drugi aspekt to niższe koszty transakcji. Fintechy i bigtechy nie mają rozbudowanych struktur, budynków na Manhattanie czy Wall Street, a także tysięcy pracowników. Mogą więc inwestować wyłącznie w technologię. Choć i tak są to duże pieniądze, a rozwój w tym zakresie jest bardzo drogi – dość powiedzieć, że w 2020 roku Amazon wydał na ten cel 40 miliardów dolarów. Oczywiście, mniejsze firmy z konkretną usługą finansową tyle nie inwestują, natomiast brak innych kosztów sprawia, że ich oferta jest efektywniejsza i tańsza.
Algorytmy i rozwiązania data science w fintechach są bardziej precyzyjne, jeśli chodzi o wyliczanie tego, co w sektorze finansowym najważniejsze, czyli niepewności. Dzieje się tak, bo wykorzystują nie tylko informacje używane przez banki w tradycyjnych modelach decyzyjnych. Dzięki temu, że funkcjonują w sektorze jeszcze wciąż mało uregulowanym, mogą sobie pozwolić na pozyskiwanie danych z różnych źródeł, chociażby z social mediów, żeby wyliczyć ryzyko kredytowe. To powoduje, że instytucja czy osoba odrzucona przez bank, np. z uwagi na brak historii kredytowej albo wcześniejszych spłat w terminie, może skorzystać z usług fintechów, które potrafią dużo precyzyjniej określić ryzyko.
Rzecz ma się podobnie w algorytmach dotyczących inwestowania – trading w większości badań jest oceniany jako dużo bardziej skuteczny i precyzyjny, dostarczający lepsze zwroty inwestorom. Część klientów przerzuca się na tego typu zdigitalizowane usługi, ponieważ są tańsze, szybsze, sprawniejsze i bardziej spersonalizowane. Nie muszę iść do banku, żeby podpisać umowę, wszystko jest załatwiane elektronicznie.
Te zmiany mają ogromny wpływ na całą gospodarkę. Dzięki skomplikowanym modelom machine learningu, które mogą precyzyjnie ocenić ryzyko i przyszłość firmy, okazało się, że przedsiębiorcy, którzy nie dostawali środków na inwestycje, nagle mogli je pozyskać. Kolejny aspekt dotyczy reakcji banków na działania bigtechów i fintechów odgrywających dużą rolę w digitalizacji sektora. Banki obudziły się i zauważyły, że już nie są same, a ich konkurenci robią się coraz poważniejsi – wiele z nich już aplikowało o licencje bankowe. Fintechy, początkowo małe, stały się międzynarodowymi instytucjami, a banki zdały sobie sprawę, że mogą przegrać w tej bitwie, co sprawiło, że same mocno zainwestowały w cyfryzację.
A jak wykorzystanie algorytmów i data science w fintechach przełożyło się na spłaty kredytów?
Odsetek błędów algorytmów, które są wykorzystywane na co dzień, jest bardzo niewielki. Natomiast jeśli chodzi o banki, to używane przez nie modele scoringowe, czyli systemy oceny pozwalające niejako klasyfikować klientów na podstawie wybranych cech, są uregulowane i akceptowane przez Komisję Nadzoru Finansowego. W związku z tym banki nie mogą wykorzystywać danych z Facebooka. Dlatego pomimo digitalizacji sektora ich modele scoringowe nie zmieniły się za bardzo. Trudno jest zatem wymagać od nich, żeby klient, który dotąd nie miał zdolności kredytowej, nagle „przeskoczył” jako ten ze zdolnością kredytową.
Jednakże na całym rynku, poza bankami, zmiana jest bardzo widoczna. Data science w fintechach wprowadza zupełnie inne modele scoringowe, wykorzystując większą ilość danych przy bardziej zaawansowanych algorytmach, na tym polega ich know-how. Dzięki temu przejmują klientów „niezagospodarowanych” przez banki.
Jednocześnie brakuje jednoznacznych badań pokazujących przełożenie fintechowych systemów na spłacalność kredytów przez klientów. Zgodnie z wynikami analiz modeli scoringowych we Francji, w przypadku MŚP ryzyko bankructwa po przyznaniu kredytu fintechowego było tylko nieznacznie wyższe od ryzyka wyliczonego przez banki. Ale już w Stanach Zjednoczonych było dużo wyższe. Dlatego raporty najczęściej wskazują, że po kredyty fintechowe idą wciąż najczęściej ci, którzy mają problem z uzyskaniem finansowania bankowego. Dlatego siłą rzeczy przy niższej zdolności kredytowej ryzyko bankructwa wzrasta. Gorsza spłacalność nie wynika więc ze złego działania algorytmów, tylko z innego typu klienta.
Co z pracownikami? Czy w branży rozmawia się o pomysłach, jak ich przebranżowić, jakie nowe zadania przypisać, żeby odnaleźli się w sektorze scyfryzowanym?
Owszem, digitalizacja powoduje zamknięcie placówek. Równocześnie w Polsce, Niemczech czy we Francji oddziały były i nadal są w każdym większym mieście, a ludzi w nich pracujących nie da się „przesunąć” gdzieś indziej. Z nowych technologii nie korzysta całe społeczeństwo – całkowite zamknięcie placówek pozbawiłoby np. starsze osoby dostępu do usług finansowych. Z tego powodu Lloyds Bank w Wielkiej Brytanii rozpoczął edukację starszej części społeczeństwa na szeroką skalę, żeby włączyć ich w transformację sektora finansowego. COVID-19 dodatkowo przyspieszył zamykanie placówek ze względów bezpieczeństwa – ludzie albo nie chcieli, albo nie mogli przychodzić do oddziałów.
Cyfryzacja sektora obejmie dużą część obsługi klienta detalicznego, a także produktów dla przedsiębiorców. W mniejszym stopniu będzie dotyczyła tych bardziej specjalistycznych gałęzi, takich jak zarządzanie majątkiem, gdzie relacje pomiędzy bankierem a klientem są bardzo ważne. Jakiś czas temu prowadziłam badanie w Szwajcarii dla banku, który specjalizuje się w zarządzaniu majątkiem bogatych klientów.
Z wywiadów wynikało, że klienci chętnie bawią się nową technologią, ale chcą mieć swojego doradcę. W mniejszym stopniu cyfryzacja obejmie też doradztwo w kwestii fuzji i przejęć czy restrukturyzacji, czyli te obszary, gdzie liczą się relacje. Natomiast procesy związane z analizami, podejmowaniem decyzji i modelami scoringowymi będą scyfryzowane, co de facto oznacza, że proces obejmie trzy czwarte sektora bankowego.
Czy oznacza to również, że digitalizacja będzie miała wpływ na podobny odsetek pracowników?
Myślę, że nie będzie to aż tak dużo, bo ktoś musi kontrolować działanie algorytmów. Moim studentom pokazywałam przykład algorytmu Google’a szkolonego w rozpoznawaniu pieska chihuahua. Na podstawie kilkuset zdjęć algorytm rozpoznawał cechy charakterystyczne zwierzęcia. Aby sprawdzić, jak sobie radzi, pokazano mu również zdjęcie babeczki z jagodami, które program zaklasyfikował jako oczy pieska. Innym przykładem było zdjęcie owiec posadzonych na drzewie, które robot wziął za żyrafę.
Choć algorytmom blisko do perfekcji, to pokazuje, że jeszcze jej nie osiągnęły, dlatego niezbędny jest człowiek sprawdzający wyniki. Poza tym ciągle brakuje regulacji – w większości krajów roboty nie mogą decydować w sektorze finansowym, pod każdą decyzją musi się podpisać człowiek. Sektor bankowy będzie jednym z najbardziej dotkniętych digitalizacją, co nie oznacza jednak, że nie będzie w nim w ogóle ludzi. Automatyzacja nie pójdzie bowiem tak daleko. Na końcu i tak ktoś musi kontrolować, co dzieje się z danym kredytem.
Czy spotkała się Pani z sytuacją interwencji człowieka w przypadku, gdy algorytm pomylił się w decyzji związanej z finansami?
Takie przypadki były, ale wiązały się raczej z błędami ludzkimi. Zdarzało się, że algorytm był źle napisany, co jest wpisane w ryzyko transformacji cyfrowej. Sama widziałam modele, które przy niskim poziomie ryzyka inwestycyjnego doradzały 98 proc. inwestycji w akcje. Inny przykład to podanie złych danych algorytmowi, który podejmował decyzje podchodzące pod dyskryminację.
Znane są też przykłady błędów algorytmów, które doprowadziły do tzw. flash crashes, czyli bardzo szybkich spadków wartości jakichś aktywów na rynkach, a także błędów ludzkich takich jak w przypadku Knight Capital. Dlatego coraz częściej się mówi, że algorytmy nie mogą być czarnymi skrzynkami, szczególnie w przypadku fintechów, bo banki pod tym względem są restrykcyjnie kontrolowane.
Większość innych instytucji zajmujących się w jakiś sposób finansami była przez długi czas nienadzorowana. W przypadku negatywnej decyzji bank musi wyjaśnić, dlaczego podaje decyzje odmowną, a odpowiedź, że „algorytm tak zadecydował”, nie jest zgodna z prawem. Zatem powinniśmy rozumieć, co algorytmy robią, żeby mieć wpływ na podejmowanie decyzji. Należy również oczekiwać, że obszar ten będzie coraz bardziej uregulowany.
Patrząc z perspektywy klienta, który już korzysta ze scyfryzowanych usług, czego możemy się spodziewać w przyszłości?
Tylko dobrych rzeczy (śmiech). Klient oczekuje produktu spersonalizowanego i taniego, szybkich decyzji, a także dostępu do swoich finansów z każdego zakątka świata. Digitalizacja zmniejsza koszty, czego dobrym przykładem jest Revolut, którego jedni nienawidzą, a inni uwielbiają. Nie możemy jednak wątpić, że wymusił dużą zmianę w zakresie płatności w walutach. Osobiście nie znam nikogo, kto wyjeżdżając za granicę, nie korzysta z karty Revoluta.
Największe banki na świecie – JP Morgan i Goldman Sachs – zainwestowały w blockchain, żeby zmniejszać koszty transakcyjne i czas, aby wysyłając przelewy międzynarodowe, nie trzeba było czekać dwa tygodnie. Obecnie jest to nie do pomyślenia. Wchodzimy do internetu i korzystamy z usług banków lub fintechów, a pieniądze docierają natychmiast bez olbrzymich kosztów transakcji. Digitalizacja jest pozytywna dla klienta.
Natomiast nie jest wolna od ryzyk, np. wycieku danych i cyberataków. Mam na myśli nie tyle banki, chociaż te też są narażone na ataki hakerskie i wyłudzenia, ile fintechy, co do których nie jestem przekonana, czy mają takie systemy kontroli i zabezpieczeń jak banki.
Drugie ryzyko jest związane z wyciekiem danych o nas, ponieważ instytucje finansowe nie tylko gromadzą informacje o tym, co robimy z pieniędzmi, ile zarabiamy czy dokąd podróżujemy, ale coraz więcej fintechów podpina swoje usługi do różnych aplikacji mobilnych dotyczących zdrowia, uprawiania sportu czy danych medycznych. To powoduje, że będą wiedziały o nas niemal wszystko i w momencie wycieku okaże się, że w internecie krążą bardzo poufne informacje o naszych chorobach czy majątku.
Kolejnym zagrożeniem jest to, że duża część algorytmów podejmujących decyzje wykorzystuje te same albo podobne dane, co powoduje prawdopodobieństwo dużej korelacji w decyzjach i rosnącego ryzyka systemowego. Bo jeśli kredyty dostają klienci o specyficznych charakterystykach, to w przypadku, gdy zdarzenie systemowe lub rynkowe dotknie tę konkretną grupę, straty obejmą nie jedną instytucję, ale wszystkie, które korzystały z danego algorytmu.
Identyfikuję to ryzyko, bo tak naprawdę mamy dwóch, góra trzech dostawców technologii. Choć algorytmy są w dużej mierze czarnymi skrzynkami, to korzystanie z usług tych samych producentów sprawia, że ryzyko korelacji ich działania rośnie. Nawet jeżeli zostaną dopasowane do potrzeb poszczególnych instytucji, to gros danych, których potrzebują do analiz, będzie się pokrywało. Dlatego ewentualnego krachu nie będziemy mieli w jednym kraju, ani w trzech, tylko może się okazać, że kryzys dotknie połowę świata, bo największe banki miały podobne procesy decyzyjne.
Czy inne branże wykorzystują dane instytucji finansowych? Czy są jakieś projekty wspólne?
Dyrektywa PSD2 (ang. Payment Services Directive) zezwala bankom na udostępnienie danych klienta instytucjom czy podmiotom trzecim. Oczywiście, klient musi wyrazić zgodę i najczęściej robi to chętnie, jeśli widzi w tym jakąś korzyść – na przykład wtedy, gdy może kupić coś taniej. Zatem PSD2 otworzyła drogę różnym podmiotom, które wykorzystują te dane dla różnych celów.
Z finansowego punktu widzenia mogę dostać propozycję, jak zainwestować swoje środki, na podstawie analizy moich wydatków i zachowań. Czemu nie, skoro podmiot trzeci może mi coś takiego przygotować. Albo otrzymam coś w stylu personal finance – algorytm widzi, że często podróżuję, więc proponuje mi kartę z niskim albo bez żadnego spreadu, jeśli chodzi o kurs walutowy. Dotyczy to też ubezpieczeń – im więcej danych firmy ubezpieczeniowe będą o nas miały, tym lepsze warunki zaproponują.
Nad jakimi projektami Pani obecnie pracuje?
Pierwszy dotyczy dyskryminacji w algorytmach – badamy, jak powszechny jest to problem, jakie typy algorytmów mają tendencję do dyskryminacji i dlaczego to robią. Ten projekt dopiero pączkuje, jest realizowany w ramach konsorcjum z czterema instytucjami.
Drugi, który prowadzimy we współpracy z University College London, dotyczy digitalizacji w sektorze finansowym i dostępu do finansowania małych i średnich przedsiębiorstw. Wpisuje się to w politykę Unii Europejskiej, która otwarcie mówi, że proces digitalizacji sektora powinien wpłynąć pozytywnie na te podmioty, które były dotąd pomijane przez banki komercyjne. W tym kontekście mówi się właśnie o małych i średnich przedsiębiorstwach pomimo tego, że tworzą najwięcej miejsc pracy, mają największy udział w PKB i w największym stopniu przyczyniają się do rozwoju know-how w danym kraju.
Z tym wiąże się kolejne badanie, które sprawdzi, czy cyfryzacja w sektorze MŚP rzeczywiście powoduje zwiększenie ich wydatków na inwestycje. Z kolei ostatni projekt dotyczy ryzyka systemowego – szukamy odpowiedzi na pytanie, jak decyzje podejmowane przez algorytmy i narzędzia data science w fintechach i bigtechach wpływają na ryzyko, jakie może powstać w sektorze finansowym. Zebraliśmy dane dla 55 największych banków w Europie i Stanach Zjednoczonych i patrzymy, z jakich rozwiązań technologicznych korzystają one oraz kto te rozwiązania dostarcza.
Czy jest coś, co dzisiaj możemy poprawić w algorytmach?
Algorytmy nie są perfekcyjne. Mają tzw. bias, czyli pewne błędy już udowodnione przez naukę. Przykładem mogą być różne formy dyskryminacji w algorytmach. To szerokie pojęcie, bo widzimy tutaj dyskryminację płci, ale też geograficzną czy pod względem edukacji, które wynikają z danych historycznych i innych informacji, które dostarczamy modelowi. Myślę, że wraz z analizą, a także lepszym poznaniem elementów i sposobów działania algorytmów będziemy w stanie wykrywać błędy. Na razie możemy porównywać działanie robotów w skali makro.
Trzeba pamiętać, że ten rynek dopiero się rozwija – na początku używał tylko twardych danych o naszej sytuacji życiowej, zarobkach, zatrudnieniu czy lokalizacji. Później okazało się, że można zbierać kolejne informacje. Teraz mówi się, że będzie ich jeszcze więcej, czyli algorytmy będą się uczyły. Dlatego z lepszym poznaniem „wnętrz” algorytmów i działaniami korygującymi algorytmy będą coraz precyzyjniejsze.
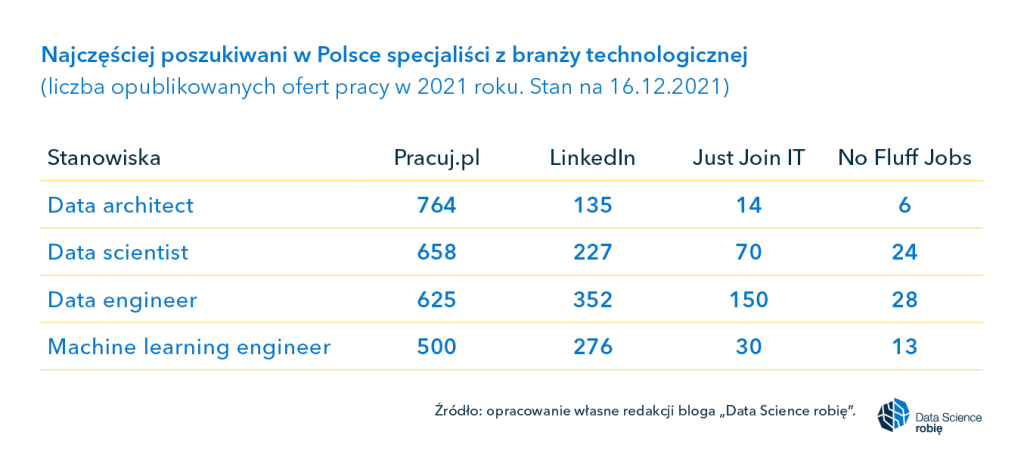
Niemal 4 tysiące – to sumaryczna liczba ofert dla specjalistów od data science, data engineering, machine learning engineering i data architecture opublikowanych na wiodących w Polsce portalach z ogłoszeniami o pracę. A to dopiero początek, bo serwisy te przewidują dalsze wzrosty ofert dla ekspertów z branży w kolejnych miesiącach.
Data architect, data scientist i ML engineer… Postępująca rewolucja związana z rozwojem gospodarki cyfrowej nie mogłaby zaistnieć bez wyspecjalizowanych kadr. Kto jest dziś rozchwytywany w branży technologicznej?
Kogo potrzebujemy już dziś?
Jak czytamy na blogu platformy edukacyjnej FutureLearn, data scientist, machine learning engineer, data engineer i data architect to 4 specjalizacje, które są obecnie najczęściej poszukiwane w świecie danych na brytyjskim rynku pracy. A jak to wygląda w krajach bliższych Polsce?
Jednym z przykładów są nasi zachodni sąsiedzi Niemcy oraz – porównywana z Polską w kontekstach gospodarczym, demograficznym czy geograficznym – Hiszpania. Ciekawe zestawienie najbardziej popularnych zawodów w branży IT za 2020 rok dla tych państw przygotował portal LinkedIn. Badanie powstało na bazie danych o ofertach pracy opublikowanych w serwisie. W serii raportów pod nazwą „The fastest-growing jobs in the world” LinkedIn wyróżnia m.in. rynek pracy dla Niemiec czy Hiszpanii. Także w przestrzeni sztucznej inteligencji oraz data science.
Okazuje się, że w Niemczech zapotrzebowanie na pracowników w tym obszarze od lat rośnie, co nie powinno dziwić. Co ciekawe, większość nowo zatrudnionych na tym rynku pracowników w AI i data science zostało przejętych przez Amazon. Wpływ na to miał rozwój e-commerce w trakcie pandemii. Do najczęściej poszukiwanych w Niemczech stanowisk należały m.in. machine learning researcher i data science specialist.
Z kolei w Hiszpanii ma miejsce prawdziwy boom na rozwiązania sztucznej inteligencji. Kraj ten ogłosił, że zainwestuje 600 mln euro w AI w ciągu najbliższych dwóch lat w ramach planu transformacji swojej gospodarki narodowej. Nic więc dziwnego, że liczba miejsc pracy w sektorze technologicznym wzrosła w 2020 roku aż o 64 proc. Najbardziej pożądane zawody to data science specialist i artificial intelligence specialist.
Data scientist i data engineer w polskim topie
Wiemy już, co czeka na specjalistów od data science, machine learningu czy sztucznej inteligencji w Wielkiej Brytanii, Hiszpanii i Niemczech. Jednak w przypadku naszego kraju trudno znaleźć liczbowe zestawienia najbardziej popularnych zawodów czy specjalizacji z obszaru data science.
Więcej światła na tę kwestię rzuca przyjrzenie się ofertom wyświetlanym w popularnych serwisach „pracowych”. Przejrzeliśmy pod tym kątem zarówno duże portale jak Pracuj.pl czy LinkedIn, jak i te mniejsze lub branżowe prowadzone przez Devire, JustJoinIT czy NoFluffJobs. Te dwa ostatnie de facto publikują wyłącznie oferty pracy z branży technologicznej.
Pozyskane przez nas dane o najpopularniejszych zawodach po ich nazwach wskazywałyby na przewagę ofert dla specjalistów od data engineering i data science. Przypadek? Kolejne miejsce zajmują takie pozycje jak machine learning engineer czy data architect. Czy jest wśród nich popularny w Hiszpanii data science specialist? Tu dochodzimy do kwestii nazewnictwa – w różnych krajach stanowiska ta są różnie tłumaczone.
Jeden z portali z ofertami pracy poinformował nas, że w ich przypadku oferty dla data scientist i data engineer często występują wymiennie, mimo że na ogół są to dwie różne specjalizacje. Ten pierwszy jest bardziej analitykiem niż programistą, a ten drugi na odwrót. Ich funkcje, zadania czy powierzone im projekty mogą być podobne. Dlatego pracodawcy sami podczas rozmów kwalifikacyjnych czy też poznania dotychczasowego doświadczenia kandydatów decydują, kto zostanie zatrudniony.
Dziwić może stosunkowo niewielki odsetek ofert dla data scientistów opublikowanych na przestrzeni 2021 roku w popularnych polskich serwisach. Choć ta specjalizacja zdobywa coraz większą popularność, to na jednym z portali propozycje dla data scientistów stanowiły tylko 0,4 proc. wszystkich ofert z obszaru IT w zeszłym roku.
Poniżej przytaczamy dane na temat liczby opublikowanych ofert dla najpopularniejszych zawodów w branży technologicznej za 2021 rok. Informacje udostępnione zostały przez 4 wiodące serwisy do zamieszczania ogłoszeń o pracę – Pracuj.pl, LinkedIn, Just Join IT i No Fluff Jobs.
Data scientist i ML engineer są potrzebni światu
Według badania przeprowadzonego przez Markets and Markets rynek platform data science osiągnął w 2019 roku wartość około 37,9 mld dolarów, a do 2024 roku oczekuje się, że wzrośnie 4-krotnie i osiągnie pułap 140,9 mld dolarów. Nie ma więc żadnych podstaw, aby sądzić, że również w 2022 roku tendencja wzrostowa miałaby wyhamować.
Pamiętajmy, że wciąż żyjemy w pandemii. Działania zwalczające ją samą, a także jej skutki, również będą kontynuowane. A im więcej pieniędzy jest inwestowanych w analizę danych, tym większe jest zapotrzebowanie na specjalistów. Ktoś musi te dane zbierać, budować środowiska, platformy i programy do ich analizy, przetwarzać, wyciągać wnioski, tworzyć scenariusze i prognozować.
Zawody i specjalizacje z obszaru data science mogą się okazać kluczowe nie tylko dla rozwoju szeroko rozumianej branży technologicznej czy biznesu, ale tak naprawdę dać szansę na zmianę naszego świata na lepsze. Przede wszystkim na uczynienie go bardziej zrozumiałym, przewidywalnym. Możliwe, że dane i ich skuteczna analiza pozwolą również stworzyć narzędzia do walki z tym, czego przewidzieć się nie da.
– Nikt nie połączył jeszcze sprawności układu nerwowego człowieka z jakością gry. Dzięki naszej technologii przeprowadzimy amatora do etapu rozgrywek z najlepszymi zawodnikami. To jest rewolucja data science w gamingu – podkreśla Maciej Skorko, współzałożyciel i dyrektor zarządzający firmy esportsLAB.
Maciej Skorko jest psychologiem z Instytutu Psychologii Polskiej Akademii Nauk. Przedsiębiorca, pomysłodawca i twórca kilku start-upów, w tym spółki PredictWatch, która tworzy oparte na sztucznej inteligencji innowacyjne aplikacje mobilne, pozwalające na przewidywanie ryzyka zachowań nałogowych i zapobiegania nawrotom tzw. głodu nałogowego. Z kolei w esportsLAB, za pomocą danych połączonych z wiedzą o układzie nerwowym człowieka oraz wykorzystania rozwiązań data science w gamingu, określa potencjał e-graczy oraz ich perspektywy zawodowe, pomagając doskonalić kompetencje gamerskie.
Wielu graczy myśli, że są całkiem dobrzy w strzelanki. Potem przychodzi brutalna rzeczywistość i weryfikacja z innymi w sieci. Czy wykorzystując data science w gamingu, możemy polepszyć ich umiejętności w grach?
Do tego właśnie dążymy. Chcemy, aby dzięki naszym rozwiązaniom zawodnicy e-sportowi, zarówno ci początkujący, jak i bardziej profesjonalni, mogli podnosić swoje umiejętności. Bazując na naszych modelach, jesteśmy w stanie ocenić, w jakiej grze początkujący gamer będzie osiągał najlepsze rezultaty, bo ma do tego predyspozycje. Wiemy, w jakim gatunku gier się sprawdzi oraz czy jest predysponowany np. do tzw. strzelanek lub gier typu moba (ang. multiplayer online battle arena). Możemy też ocenić, jaką rolę czy pozycję w zespole będzie realizował najlepiej.
Od kiedy temat danych jest ważny w e-sporcie?
Od momentu, kiedy na świecie zrodziła się idea sportów elektronicznych i powstała potrzeba oceny skuteczności graczy. Na początku opierała się wyłącznie na intuicji. Nie było danych, które pozwalałyby ją sformułować. Zawodnicy szukali rozwiązań na własną rękę, aby osiągać lepsze efekty. Szybko w e-sporcie pojawiły się duże pieniądze. Dziś zawodnicy grają na bardzo wysokim poziomie, mają porównywalnie dobry jakościowo sprzęt. Jak zatem zbudować przewagę w sytuacji, gdy niemal wszyscy funkcjonują w podobnych warunkach? Tylko poprzez skuteczną analizę danych.
Czy profesjonalne drużyny, które gromadzą dane, wiedzą, jak je przetwarzać i wyciągać z nich wnioski?
To jest największy paradoks. Najbardziej powszechny schemat analizy gry wygląda następująco: podczas odtwarzania zapisu rozgrywki trener odnotowuje najważniejsze błędy indywidualne i zespołowe. Następnie dokonuje analizy z zawodnikami. Dane w e-sporcie są więc analizowane na bardzo podstawowym poziomie. Dzieje się tak pomimo dużej dostępności informacji, jaka cechuje sporty elektroniczne. To dziś nie wystarczy, jeśli chcemy rywalizować na najwyższym poziomie czy do niego aspirować. Dodatkowo sprawę utrudniają producenci gier, ograniczając często zakres dostępnych danych. To niesie za sobą określone problemy.
To znaczy?
Większość wydawców decyduje się na ograniczony dostęp dla analityków do danych z gry. Takim przykładem jest najpopularniejsza na świecie gra “League of Legends” i jej wydawca Riot Gaming. Analitycy gamingowi dostają w tym przypadku dostęp do danych wyłącznie przez API. Ten interfejs programistyczny cechuje ubogi zakres informacji. W uproszczeniu można powiedzieć, że otrzymujemy aktualizacje stanu gry raz na minutę. Tymczasem analiza na profesjonalnym poziomie dotyczy zdarzeń, które dzieją się na przestrzeni sekund, a niekiedy ułamków sekundy.
Jednocześnie są kategorie tytułów e-sportowych takie jak “CS: GO”, gdzie wydawca gry zdecydował się na bardzo szeroki dostęp do danych z powtórek meczu. Można je parsować, czyli przetwarzać i porządkować, a potem rozbijać na najmniejsze elementy. To znacznie ułatwia ich późniejszą analizę. Jednak nawet w tych przypadkach najczęściej spotykamy się z analizą jakościową, nie ilościową. Ponadto takich gier jest niewiele i są raczej wymierającym gatunkiem.
Czyli w zasadzie mówimy o danych, które albo są niewłaściwe, albo ich nie ma?
Lub nie ma do nich dostępu. To ekskluzywna wiedza, zrozumiała dla samego środowiska gamingowego, w którym – i to warto podkreślić – nie ma wielu analityków danych. Pamiętajmy też o pewnej hermetyczności zjawiska, jakim jest e-sport. Organizacje e-sportowe same dla siebie zaczęły wytwarzać metody analiz danych, ale nie dzielą się tymi wynikami z innymi. Przeciętny użytkownik nie może się dowiedzieć, jak to działa. Tym samym nie jest w stanie sam dojść do gry na najwyższym poziomie. Całe know-how, informacje czy analizy, jakie tam powstają, zostają w progamingu. Dlatego celem jest demokratyzacja wiedzy i doświadczenia profesjonalnych trenerów i analityków, tak by każdy aspirujący amator mógł zrealizować swoje marzenie o zostaniu profesjonalnym graczem.
Stąd data science w gamingu powoduje większą presję na pozyskanie wiedzy?
Oczywiście. Pragnienie, aby stać się profesjonalnym graczem, staje się coraz większe, bo w tym biznesie jest też coraz więcej pieniędzy. Zauważmy, że są takie gry jak “Fortnite”, w które można grać bez żadnej drużyny czy organizacji. Jeśli jesteś wystarczająco dobry, możesz wygrywać miliony dolarów. Mało tego, pojawiają się stypendia na uczelniach dla graczy, co do tej pory było domeną sportów tradycyjnych.
Profesjonalne zespoły nie mają jednak realnych narzędzi do tego, aby prowadzić początkujących graczy od momentu, kiedy ci aspirują do bycia profesjonalistą, do momentu stania się nim. Chętnych do gry jest coraz więcej, a więc ambicjom całej rzeszy graczy e-sport nie sprosta bez nowych technologii.
I tu pojawia się esportsLABgg…
Zbudowaliśmy coś, co przekroczyło granicę dostępu do niskopoziomowych danych z gry. Mamy nasze autorskie rozwiązanie – „computer vision for games”. Co nam daje? Przede wszystkim możliwość analizowania treści zawartości ekranu z rozdzielczością do 60 klatek na sekundę i zapisywania bardzo wielu szczegółowych informacji na temat tego, co się podczas danej rozgrywki wydarzyło. Pozyskujemy informacje, jakie były decyzje, które podejmowali zawodnicy, oraz gdzie się znajdowali, kiedy je podejmowali. Ta technologia daje możliwość tworzenia zbiorów danych, które do tej pory były niedostępne dla analityków, nie mówiąc już o trenerach czy zawodnikach.
No dobrze, ale przecież sama gra też zlicza podobne zdarzenia. Mamy informacje o tym, jak zawodnik poradził sobie w tej grze, ile miał asyst, ile obrażeń zadał. To po co nam informacja jeszcze o tym, gdzie ktoś się znajduje?
Chodzi o “game knowledge” – wiedzę o grze. Jest to warstwa rozumienia rozgrywki, która powstaje wokół każdego tytułu granego na profesjonalnym poziomie, jako nadbudowa podstawowych mechanik gry. Właśnie to odróżnia dwóch zawodników o zbliżonym poziomie umiejętności manualnych. W zakresie obsługi mechaniki gry każdy z nas dojdzie do pewnego pułapu, który jest wyznaczony przez parametry naszego układu nerwowego.
I co dalej?
W większości wypadków dojdziemy do wysokiego poziomu, poświęcając wiele czasu na grę. Ale co się dzieje, gdy już się na nim znajdziemy? Tam „na samej górze” wszyscy są tacy jak my. Mają podobne umiejętności. Na tym pułapie gry zaczynają decydować już całkowicie inne kwestie. Mianowicie to, jak jestem w stanie użyć podstawowych umiejętności manualnych, które nabyłem, do tego, żeby mieć przewagę taktyczną nad przeciwnikiem.
I Wy taką przewagę możecie wskazać?
Największym potencjałem naszego rozwiązania jest to, że możemy zrozumieć i symulować ocenę gry, jakiej dokonałby profesjonalny trener czy analityk. Taki, który nie patrzy, czy ty dobrze strzelasz, bo wszyscy zawodnicy na tym poziomie dobrze strzelają. On patrzy na twoje najdrobniejsze błędy i to, z czego one wynikają, jakie niosą konsekwencje w krótkim i długim okresie trwania rozgrywki.
Tworzycie zatem coś w rodzaju asystenta specjalisty od data science w gamingu, jednak go nie zastępujecie?
Możemy, ale nie musimy. Wystarczy, że nasze rozwiązanie zrobi 60 proc. pracy za analityka, i to już jest wartość dodana zarówno dla profesjonalistów, jak i amatorów. Moim zdaniem najważniejsze jest to, że dzięki takiej analizie mamy możliwość docelowo zdemokratyzować profesjonalny gaming.
Brzmi jak rewolucyjne hasło.
Ponieważ to jest rewolucyjne rozwiązanie. Chcemy, aby człowiek taki jak my miał realną szansę zrozumieć, czego musi się nauczyć, żeby próbować gry na najwyższym poziomie. Nasze podejście pozwoli na zbudowanie narzędzia, które przeprowadzi amatora aspirującego do najwyższego pułapu gry do momentu, w którym będzie mógł spróbować zmierzyć się z najlepszymi.
To dla poszczególnych zawodników. A co zyskają drużyny?
Dla organizacji to narzędzie pozwoli skutecznie wybierać tych ludzi spośród wszystkich aspirujących, którzy będą dawali jakąkolwiek nadzieję na wysoki poziom rozgrywki. Będą dobrze uzupełniać luki, braki, które się dziś pojawiają w zespole. To szansa na pozyskanie talentów, szybszą adaptację w drużynie, przyspieszenie onboardingu.
Mówimy o e-sporcie. Ale co w przypadku tradycyjnych dyscyplin – czy to rozwiązanie jest adaptowalne?
W przypadku sportów tradycyjnych oczywiście pojawiają się te same problemy, ale też podobne dane. Przecież stadiony czy boiska treningowe są naszpikowane setkami kamer, aby wychwycić niuanse, zachowania graczy, techniczne braki czy umiejętności. Dla trenera sportowego taka analiza jest niezwykle trudna, podczas gdy dla technologii już nie. Muszę jednak przyznać, że w sporcie tradycjonalnym te dane są trudniejsze do pozyskania niż w sportach elektronicznych.
Nie mówimy jednak nie. Dla mnie kolejnym krokiem po opanowaniu e-sportu i pokazaniu skuteczności tego rozwiązania na pewno będzie przenoszenie tych doświadczeń na konwencjonalne dziedziny sportowe.
Analizujecie dane wideo, dane statystyczne, bieżące aktywności… Czy data science w gamingu pozwala też analizować ludzkie cechy fizyczne czy osobowościowe?
Oczywiście w trakcie gry ważny jest jeszcze kontekst, kim jesteś jako osoba. Jakie są twoje cechy temperamentu, szybkość reakcji, zdolność do dostrzegania obiektów na peryferiach pola widzenia, a także poziom aktywności fizycznej. Dlatego istotne jest też pozyskanie danych na temat parametrów układu nerwowego. Dodatkowo dochodzi kwestia interfejsu. Badamy to, jak reagujesz na różne bodźce i wydarzenia w grze, jak twoje dłonie pracują na interfejsie mysz – klawiatura. I z tych informacji jesteśmy w stanie pozyskać wiedzę o tym, jak grasz w danym momencie.
Odpowiadamy na pytania o to, czy potrzebujesz rozgrzewki, jak wyglądają parametry twojego snu, kiedy będziesz w optymalnej formie. To jest cały obszar danych, które opisują, kim jesteśmy jako ludzie, a które pozwolą nam także przewidywać talent w e-sporcie czy predyspozycje do grania.
Wydaje się, że to bardzo komplementarne rozwiązanie. Jaką przyszłość widzisz dla niego w najbliższych latach?
Mamy wielką szansę dokonać do tej pory niemożliwego – odpowiedzieć na potrzeby wynikające z ambicji profesjonalnych graczy. E-sport przez lata wykształcił ogromny know-how. I to bez używania jakichkolwiek analitycznych narzędzi. Dlatego nasza praca jest stosunkowo prosta. My mamy zebrać dane, zrozumieć, jak je analizować, a następnie zbudować narzędzia.
Takich usług analitycznych, które współpracują z profesjonalnym gamingiem, jest na rynku bardzo mało. My postawiliśmy na progaming, stworzyliśmy potrzebne narzędzia, zabraliśmy e-sportowców z epoki Excela do epoki aplikacji. Dołożyliśmy do tego nasze źródła danych, metody zautomatyzowanej analizy i w ten sposób dostarczamy im wartość. Jesteśmy pionierami w tej dziedzinie. Nikt się nie zastanawiał do tej pory, jak ma się sprawność układu nerwowego człowieka do jakości gry. Jesteśmy pierwszą firmą, która tak na to wnikliwie patrzy.
Naszą najbliższą przyszłością są oczywiście usługi dla amatorów sportów elektronicznych.
Muszę zapytać o skuteczność takiego sposobu wykorzystania data science w gamingu. Czy technologia była już testowana, wdrażana?
Nasze rozwiązanie w obszarze selekcji graczy już przynosi efekty. Przykładem jest polska drużyna e-sportowa AGO. Wyłowiliśmy dla nich tymi metodami dwóch graczy, którzy dzisiaj są gwiazdami młodego pokolenia. Co ważne, swoje rekomendacje wypracowaliśmy na bazie sprawności układu nerwowego tych zawodników. Podobne sukcesy odnotowaliśmy też przy selekcji na większą skalę w projekcie Dr Pepper Academy.
Teraz pracujemy nad udostępnieniem tych narzędzi możliwie dużej liczbie amatorów. Chcemy, by każdy mógł stworzyć swoją kartę zawodnika i dać sobie szansę na bycie dostrzeżonym przez profesjonalne zespoły.
A co z błędami? Czy taka analiza może je w jakiś sposób generować?
Jeśli wyobrazimy sobie, że do tej pory wszelkie mankamenty gry były wychwytywane, ponieważ ktoś, oglądając powtórkę meczu e-sportowego, zapisywał wnioski w notesie, to każda osoba zajmująca się data science może sobie tylko wyobrazić, ile tzw. biasów czy zakrzywień perspektywy po drodze mogło się w tym miejscu pojawić.
To nijak ma się do sytuacji, kiedy można analizować każdą sekundę gry. Każdy moment, kiedy gracz pojawia się w tym czy w innym miejscu na ekranie z konkretną aktywnością. A najlepsze i najbardziej spektakularne w tym wszystkim jest to, że dzięki naszemu rozwiązaniu będzie można ocenić swoje predyspozycje wyłącznie na podstawie tego, jak grasz.
Obecność w sieci powoduje tworzenie tzw. śladu cyfrowego. Obecność w grze także. Czy dzięki data science w gamingu można ten ślad analizować?
Bezsprzecznie tak. Coraz więcej czasu poświęcamy na gry i ślad cyfrowy, który tam zostawiamy, jest bardzo gęsty i złożony. Tak bardzo, jak zaawansowana jest interakcja człowieka ze środowiskiem gry. Dotyczy to zarówno sprawności umysłu, i tego, jak radzimy sobie z rozwiązywaniem problemów w grze. Dzięki śladowi cyfrowemu możemy też poznać techniczny aspekt tego zagadnienia, czyli sposób wykorzystywania sprzętu do gry. Ma to duże znaczenie aplikacyjne, które można wprost przekładać na jakieś użyteczne biznesowo rozwiązania, wsparcie marketingowe, serwis itd.
Duże znaczenie ma dla Ciebie wirtualna rzeczywistość i jej możliwości rozwoju oraz analizy danych.
Jednym z takich dzieł mojego życia, które dziś kontynuuję z dr. Grzegorzem Pochwatko w Instytucie Psychologii PAN, jest VR Lab – laboratorium rzeczywistości wirtualnej i psychofizjologii. W tym laboratorium zespół Grześka realizuje ideę analizy zachowania człowieka i wpływu na jego układ nerwowy poprzez wykorzystanie rzeczywistości wirtualnej. Jestem jej ogromnym entuzjastą.
Dzięki rozwiązaniom VR możemy prowadzić badania, które pozwolą pokazać, jak funkcjonujemy w symulacjach rzeczywistości. I jak reaguje na to nasz mózg. Jednocześnie minimalizujemy ewentualne błędy wynikające z bodźców zewnętrznych, gdyby to samo badanie przeprowadzić w środowisku naturalnym. VR jest idealny do tego, ponieważ można tworzyć złożone sceny bez żadnych ograniczeń. Każda z nich może być taka sama dla każdego uczestnika badania, a nad bodźcami mamy pełną kontrolę.
Metawersum to coraz częściej podnoszona kwestia przez wielu twórców, wizjonerów i biznes. Jaka czeka nas przyszłość, jeśli przeniesiemy się do świata VR, co obiecuje nam choćby Mark Zuckerberg w najbliższym czasie?
Ten ślad cyfrowy będzie jeszcze bardziej złożony, ponieważ ludzie coraz więcej swoich naturalnych zachowań będą przenosić ze świata rzeczywistego do tego wirtualnego. Wcale nie dziwię się, że Facebook chce stworzyć metawersum. Dzisiaj na rynku już jest wiele headsetów VR, które są zintegrowane z technologiami pozwalającymi na analizę aktywności elektrycznej kory mózgu. To jest narzędzie, które pozwala na wiele interpretacji, badań i analiz. Może nie pokazuje wprost, o czym myślisz, ale to, jak się czujesz, czy coś ci się podoba, czy nie podoba. To daje ogromne możliwości dla współczesnych badaczy, analityków czy działów marketingu.
To brzmi też jak poważne wyzwanie dla data scientistów.
Praca z danymi w coraz większym stopniu będzie wspierana zaawansowanymi metodami obliczeniowymi, których natura będzie zrozumiała dla coraz węższej grupy ludzi. Olbrzymie znaczenie będzie miało rozumienie matematyki, także na tym wyższym poziomie, ponieważ tam właśnie będą dokonywały się mechanizmy, które pozwolą nam obliczać duże zestawy danych.
Wyzwaniem dla analityków danych w przyszłości będzie gigantyczny wolumen danych do analizy. To nie jest już kwestia big data, ale następny poziom tego zjawiska. Jeśli dziś analizujemy dane dotyczące rozgrywki jednego gracza pod kątem jego jednej aktywności w grze, to wyobraźmy sobie, że w przyszłości będziemy analizować cały profil użytkownika funkcjonującego w danym metawersie. To nie tylko daje ogromne możliwości, ale także rzuca wyzwania naszym zdolnościom umysłowym.